Productivity features
Keyboard shortcuts
Sequential keybindings: Some annotation schemes provide keybindings
for selecting options. For tasks where there are at most 10 options,
keybindings can be assigned sequentially by default. When defining your
annotation scheme, set the sequential_key_binding field to True.
The first option will correspond to the \"1\" key, the second to the \"2\" key, ..., the tenth to the \"0\" key.
Custom keybindings: For greater control, custom keybindings can also
be configured. In this case, pass in objects into the labels field of
the annotation scheme. Each label object can take a key_value field
specifying the key that corresponds to it.
For example,
"annotation_schemes": [
{
"annotation_type": "multiselect",
"labels": [
{
"name": "Option 1",
"key_value": '1'
},
{
"name": "Option 2",
"key_value": '2'
}
]
}
]
Dynamic highlighting
Potato also includes randomized keyword highlights to aid in the annotation process. To enable dynamic highlighting, just provide a path to a tab-separated values file of keywords. The keywords file should have this format:
Word Label Schema
good* Negative Sentiment
bad* Positive Sentiment
terrible Negative Sentiment
Where the values in the Word column can be any valid regex, the value in the i p Label column corresponds to the selection label and the value in the Schema column corresponds to the annotation schema the label is listed under. A single keywords file can support multiple schemas.
Provide the path to the keywords file as the value to the
keyword_highlights_file key in the configuration file.
There is currently no way to specify the colors used through the configuration file.
Tooltips
For radio and multiselect question types, you have the option to add tooltips with more details about each response option. You can do this in two ways.
Option 1: you can enter plaintext in the tooltip field and the
unformatted text will display when you hover your mouse over the
response option.
"annotation_schemes": [
{
"annotation_type": "multiselect",
"name": "Question",
"labels": [
{
"name": "Label 1",
"tooltip": "lorem ipsum dolor",
},
]
},
]
Option 2: you can create an HTML file with formatted text (e.g.,
bold, unordered list), and pass the path to the html file to the
tooltip_file field. The formatted text will display when you hover
your mouse over the response option.
"annotation_schemes": [
{
"annotation_type": "multiselect",
"name": "Question",
"labels": [
{
"name": "Label 1",
"tooltip_file": "config/tooltips/label1_tooltip.html"
},
]
},
]
Active learning
Active learning can be enabled and configured by providing the
active_learning_config key to the configuration file. See below for a
basic example of the active learning configuration.
# This controls whether Potato will actively re-order unlabeled instances
# during annotation after a certain number of items are annotated to
# prioritize those that a basic classifier model is most uncertain about. If
# you have lots of unlabeled data, active learning can potentially help
# maximize the data you get for your "annotation budget", though if you plan
# on annotative *all* the data, active learning will have no effect.
"active_learning_config": {
"enable_active_learning": True,
# The fully specified name of an sklearn classifier object with packages,
# e.g., "sklearn.linear_model.LogisticRegression". This classifier will be
# trained on the annotated data and used to re-order the remaining
# instances.
"classifier_name": "sklearn.linear_model.LogisticRegression",
# Any kwargs that you want to pass to the classifier during instantiation
"classifier_kwargs": { },
# The fully specified name of an sklearn tokenizer object with packages,
# e.g., "sklearn.feature_extraction.text.CountVectorizer". This tokenizer
# will be used to tranform the text instances into features.
"vectorizer_name": "sklearn.feature_extraction.text.CountVectorizer",
# Any kwargs that you want to pass to the tokenizer during instantiation.
#
# NOTE: it's generally a good idea to keep the active learning classifier
# "fast" so that annotators aren't waiting long when classifying. This
# often meanings capping the number of features
"vectorizer_kwargs": { },
# When multiple annotators have labeled the same data, this option decides
# how to resolve the mulitple annotations to a single label for the
# purpose of training the active learning classifier.
"resolution_strategy": "random",
# Some part of the data should still be randomly selected (i.e., not based
# on active learning). This ensure the annotation process can still see a
# variety of unbiased samples and that the test data can be drawn from an
# empirical distribution of the data.
"random_sample_percent": 50,
# The names of all annotation schema that active learning should be run
# for. If multiple schema are provided, an instance will be prioritized
# based on its lowest certainty across all schema (i.e., the
# least-confident items).
#
# NOTE: if this field is left unset, active learning will use all schema.
"active_learning_schema": [ "favorite_food" ],
"update_rate": 5,
"max_inferred_predictions": 20,
},
Automatic task assignent
Potato allows you to easily assign annotation tasks to different annotators, this is especially userful for crowdsourcing setting where you only need one annotator to work on a fixed amount of instances.
You can edit the automatic_assignmetn section in the configureation file for this function
"automatic_assignment": {
"on": true, # set false to turn off automatic assignment
"output_filename": "task_assignment.json", # saving path of the task assignment status
"sampling_strategy:": "random", # currently we only support random assignment
"labels_per_instance": 10, # number of labels for each instance
"instance_per_annotator": 50, # number of instances assigned for each annotator
"test_question_per_annotator": 2, # number of attention test questions for each annotator
"users": []
},
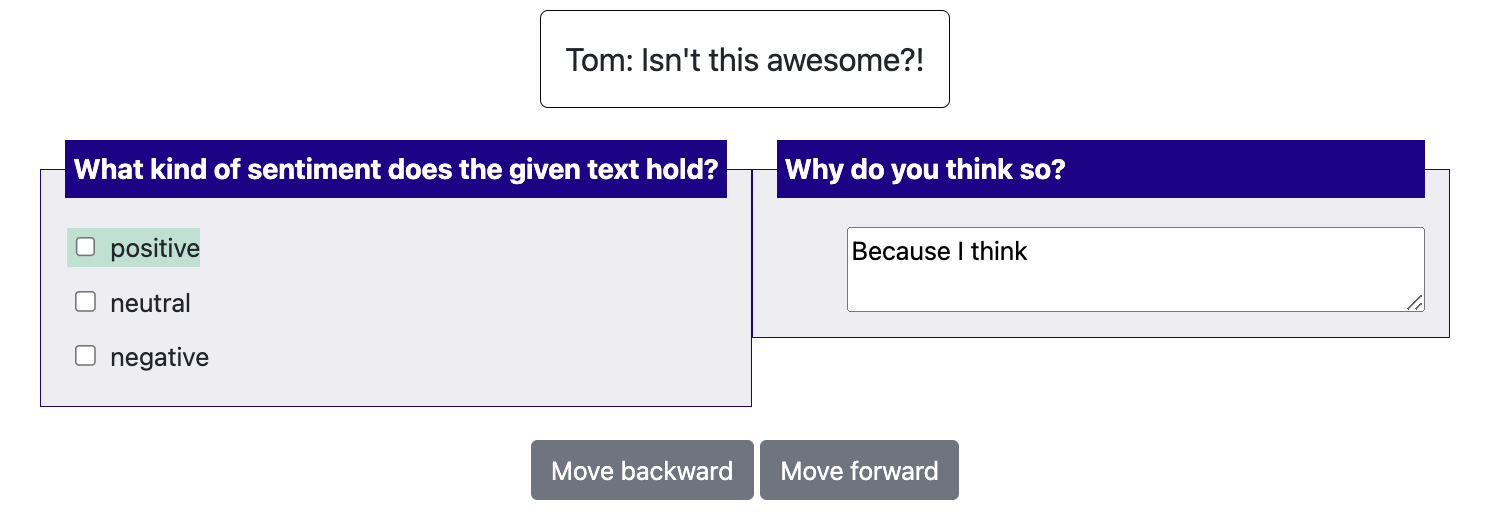
Label suggestions
Starting from 1.2.2.1, Potato supports displaying suggestions to improve the productivity of annotators. Currently we
support two types of label suggestions: prefill and highlight. prefill will automatically
pre-select the labels or prefill the text inputs for the annotators while highlight will only
highlight the text of the labels. highlight can only be used for multiselect and radio.
prefill can also be used with textboxes.
There are two steps to set up label suggestions for your annotation tasks:
Step 1: modify your configuration file
Labels suggestions are defined for each scheme. In your configuration file, you can simply add
a field named label_suggestions to specific annotation schemes. You can use different suggestion
types for different schemes.
{
"annotation_type": "multiselect",
"name": "sentiment",
"description": "What kind of sentiment does the given text hold?",
"labels": [
"positive", "neutral", "negative",
],
# If true, numbers [1-len(labels)] will be bound to each
# label. Aannotations with more than 10 are not supported with this
# simple keybinding and will need to use the full item specification
# to bind all labels to keys.
"sequential_key_binding": True,
#how to display the suggestions, currently support:
# "highlight": highlight the suggested labels with color
# "pre-select": directly prefill the suggested labels or content
# otherwise this feature is turned off
"label_suggestions":"highlight"
},
{
"annotation_type": "text",
"name": "explanation",
"description": "Why do you think so?",
# if you want to use multi-line textbox, turn on the text area and set the desired rows and cols of the textbox
"textarea": {
"on": True,
"rows": 2,
"cols": 40
},
#how to display the suggestions, currently support:
# "highlight": highlight the suggested labels with color
# "pre-select": directly prefill the suggested labels or content
# otherwise this feature is turned off
"label_suggestions": "prefill"
},
Step 2: prepare your data
For each line of your input data, you can add a field named label_suggestions. label_suggestions defines
a mapping from the scheme name to labels. For example:
{"id":"1","text":"Good Job!","label_suggestions": {"sentiment": "positive", "explanation": "Because I think "}}
{"id":"2","text":"Great work!","label_suggestions": {"sentiment": "positive", "explanation": "Because I think "}}
You can check out our example project in project hub regarding how to set up label suggestions